Monday, October 6, 2025
Memory and Context Inheritance in Agentic Systems: Design Patterns and Looking Forward

Introduction: The Memory Revolution in Agentic AI
We're witnessing a fundamental shift in AI development, moving from stateless tools to persistent, context-aware agents. The year 2025 marks a pivotal moment where memory has become the defining characteristic separating sophisticated AI agents from simple chatbots. Without proper memory systems, even the most advanced language models remain "very expensive parrots" - capable of impressive responses but lacking the continuity needed for genuine intelligence.
The transition to an agentic paradigm, where AI systems function autonomously across various tools, applications, and environments, requires persistent memory that allows these systems to reason, reflect, and take continuous action. This transformation isn't just about remembering past conversations; it's about building systems that evolve through experience, maintain coherent identities across complex multi-step tasks, and develop genuine understanding over time. The difference between a helpful chatbot and a true AI agent lies in this ability to accumulate knowledge, recognize patterns across interactions, and apply learned insights to novel situations.
Modern AI agents demonstrate their sophistication through autonomous goal pursuit, direct interaction with external systems via tools, persistent memory for maintaining context, planning capabilities for decomposing complex tasks, and continuous adaptation through experiential learning. Yet achieving this level of sophistication requires solving Hey team,
fundamental challenges that go beyond traditional machine learning. We must architect memory systems that can handle the temporal nature of information, manage conflicting updates, scale to millions of interactions, and maintain consistency across distributed agent networks—all while remaining computationally efficient and respecting privacy boundaries.
Foundational Memory Architectures
The Cognitive Hierarchy of Agent Memory
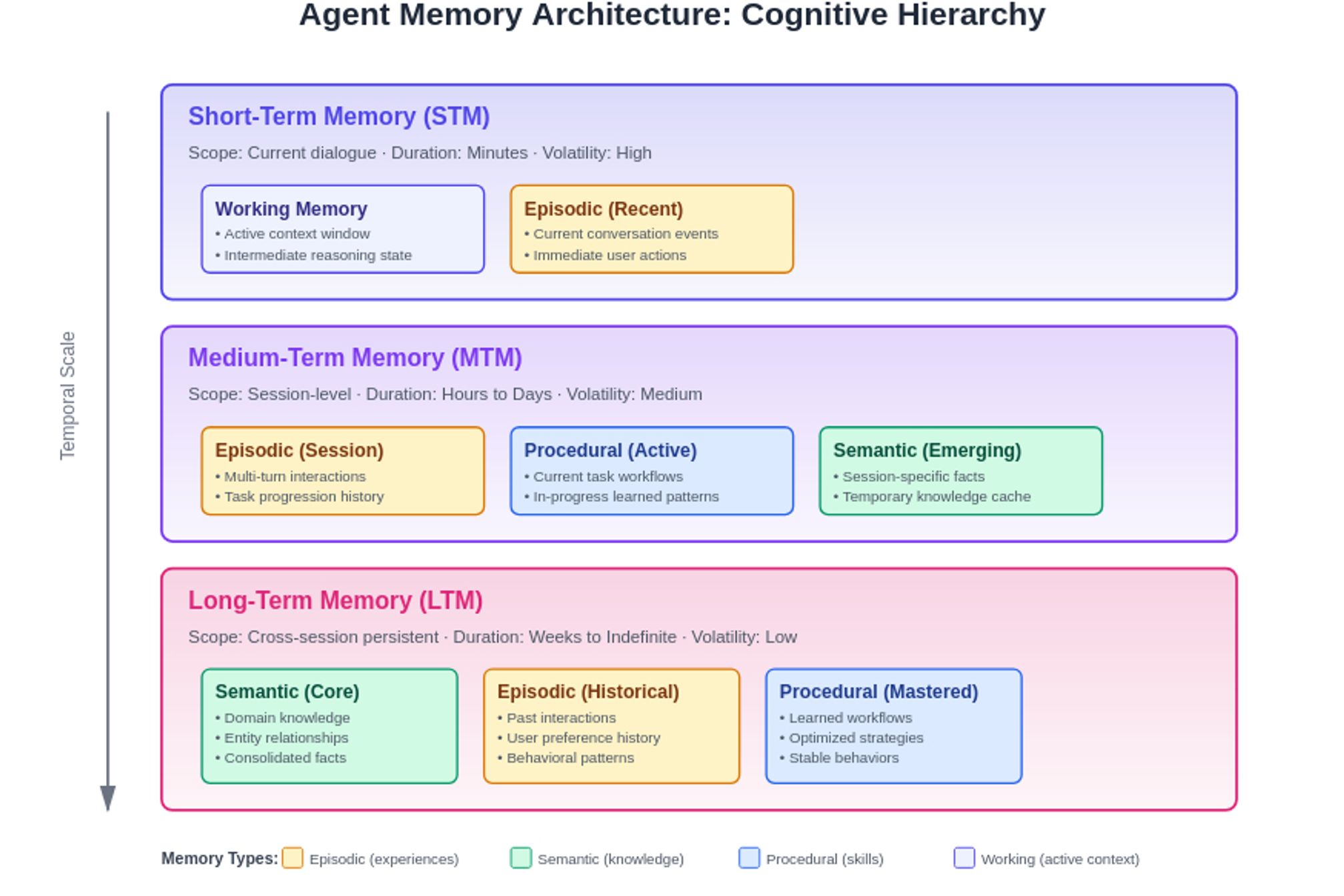
Modern agentic systems have evolved to employ sophisticated memory hierarchies that mirror human cognitive architecture. Researchers categorize agentic memory following psychological models, where short-term memory (STM) enables agents to remember recent inputs for immediate decision-making, while long-term memory provides persistent storage across sessions. This isn't merely an academic exercise—the structure fundamentally determines how agents process information and make decisions.
The MemoryOS framework exemplifies this hierarchical approach through its three-tier architecture: STM handles current dialogue context, Medium-Term Memory (MTM) maintains session-level understanding, and Long-Term Memory (LTM) preserves persistent knowledge spanning all interactions. This stratification allows agents to operate efficiently at multiple temporal scales simultaneously. An agent can maintain the flow of immediate conversation while drawing on weeks of accumulated user preferences and simultaneously accessing foundational knowledge acquired across thousands of interactions.
The sophistication extends beyond simple storage tiers. Modern agents require specialized memory types that serve distinct cognitive functions. Episodic memory captures specific experiences with rich temporal and contextual details, allowing agents to recall not just what happened, but when and under what circumstances. Semantic memory maintains the agent's understanding of facts, concepts, and relationships—the stable knowledge that forms its worldview. Procedural memory captures instructions and learned behaviors, enabling agents to remember how to perform complex tasks without re-learning them each time. Finally, working memory serves as the agent's cognitive workspace, holding active context and intermediate results during task execution.
The Dual Storage Revolution: Vectors Meet Graphs
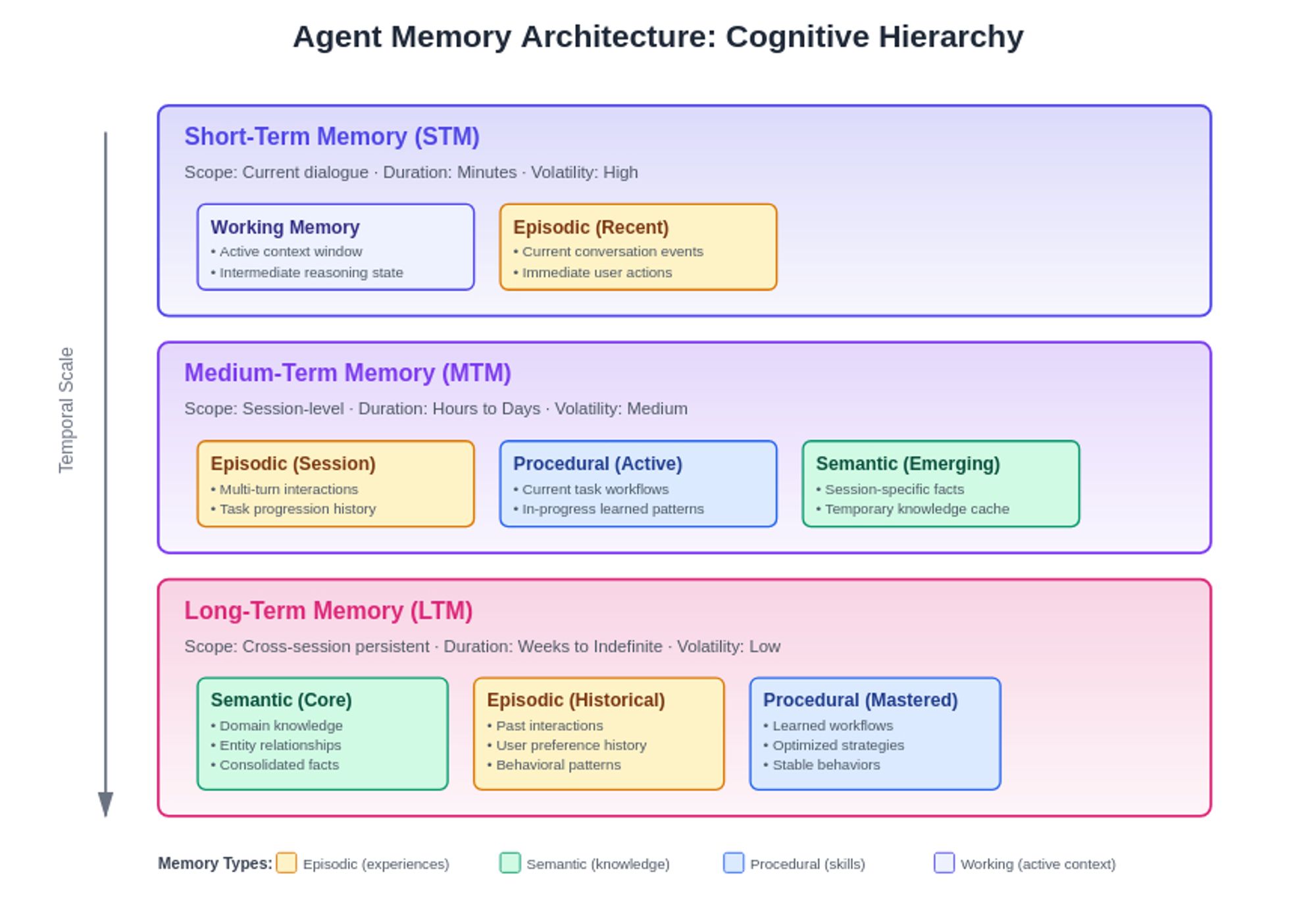
The industry has converged on a powerful dual-storage paradigm that addresses the fundamental tension between speed and sophistication in memory retrieval. Vector databases excel at fast semantic searches but lack the context and relationships necessary for complex business reasoning. They transform textual information into high-dimensional mathematical representations, enabling lightning-fast similarity searches across millions of stored memories. This makes them invaluable for the initial retrieval phase, quickly identifying potentially relevant information from vast knowledge stores.
Knowledge graphs, in contrast, excel at answering complex queries that involve traversing multiple entities and relationships, efficiently navigating graph structures to provide precise, contextually rich answers. Where vectors see similarity, graphs see structure—understanding not just that two pieces of information are related, but exactly how and why they connect. This structural understanding becomes crucial for multi-hop reasoning, where agents must follow chains of logic through interconnected facts to reach conclusions.
The real breakthrough comes from synthesizing these approaches into hybrid architectures. Graphiti, developed by Zep AI, represents this new generation of memory systems—a flexible, real-time memory layer built on temporally aware knowledge graphs stored in Neo4j, enhanced with vector and BM25 indexes that provide near-constant time access regardless of graph size. Their approach is a deep integration where vector similarity guides graph traversal, and graph structure informs semantic understanding.
Recent research from both Amazon and CMU validates this hybrid approach, showing that while Graph-Only RAG performed about 5% better than purely vector-based RAG, the real gains come from intelligent combinations of both paradigms. The vectors provide the speed and semantic flexibility needed for open-ended queries, while the graph ensures precision and maintains the logical consistency required for business-critical applications.
Context Inheritance and Engineering Patterns
Beyond Static Context: The Layered Cognitive Model
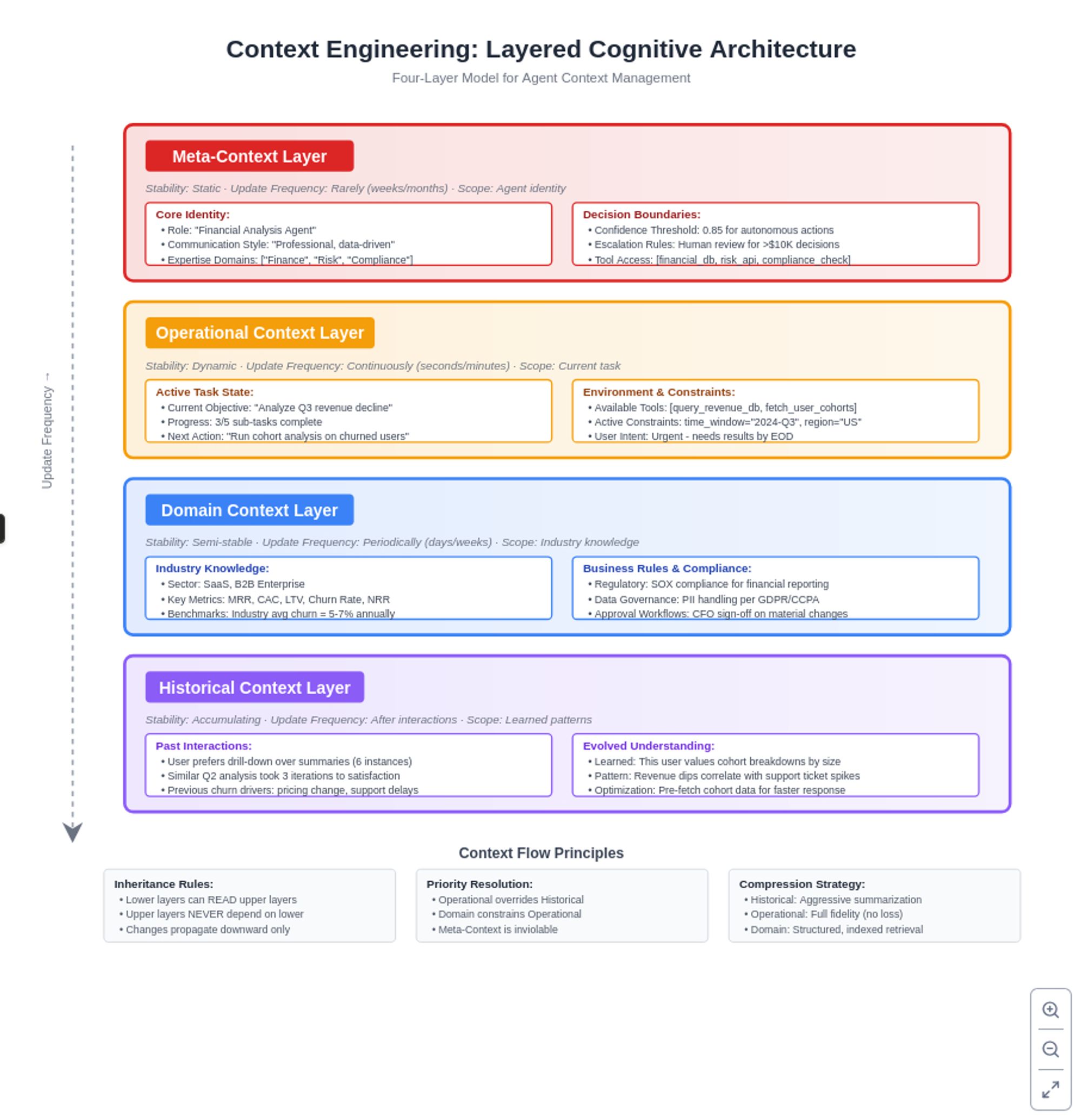
Traditional systems treat context as a static blob of information, but modern context engineering transforms agents into precision-guided thinkers through sophisticated layered cognitive models. Rather than dumping all available context into a prompt and praying the model can sort it out, we're now building structured attention mechanisms that mirror how human experts approach complex problems.
The modern context architecture typically encompasses four distinct layers, each serving a specific cognitive function.
- The meta-context layer establishes the agent's fundamental identity—its role, communication style, expertise domains, and confidence thresholds for decision-making. This foundational layer remains relatively stable, changing only when the agent's core purpose or capabilities evolve.
- The operational context layer captures the immediate task environment, including current objectives, available tools, active constraints, and user intent. This dynamic layer updates continuously as the agent navigates through task execution.
- Beneath these lies the domain context layer, encoding industry-specific knowledge, regulatory requirements, and business rules that shape the agent's decision space. This specialized knowledge allows agents to operate effectively in complex professional environments, understanding not just what's technically possible but what's appropriate given the specific domain constraints.
- Finally, the historical context layer maintains a condensed representation of past interactions, learned patterns, and evolved understanding—the accumulated wisdom that allows agents to improve over time.
Context engineering has emerged as an interesting sub-discipline for agent systems, as models may be getting stronger, but no amount of raw capability can replace the need for properly structured memory, environmental awareness, and feedback mechanisms. It is becoming essential to build dynamic systems that can prioritize, filter, and transform context based on the current cognitive demands.
Event-Driven Inheritance Patterns for Multi-Agent Systems
As we scale from single agents to complex multi-agent ecosystems, context inheritance becomes much more complex. Modern agent architectures employ specialized patterns like orchestrator-worker models, where orchestrators break down complex problems and coordinate specialized worker agents, each maintaining their own context while inheriting relevant information from the parent task. This hierarchical inheritance ensures that each agent operates with exactly the context it needs—no more, no less.
Event-driven architectures have proven particularly effective for managing context flow in multi-agent systems, with patterns like the blackboard model allowing agents to share context through a common knowledge space while maintaining their individual specialized contexts. In this model, agents don't directly pass context to each other; instead, they contribute to and draw from a shared contextual pool, with event triggers determining when each agent should update its local context from the shared state.
When agents collaborate on shared tasks, they need selective context inheritance rules that determine what information flows between agents, how conflicts are resolved, and when parent context should override local understanding. This selective inheritance prevents context pollution while ensuring critical information propagates through the agent network.
In production, implementations increasingly rely on explicit state machines and deterministic context transitions to ensure reliability, with frameworks providing built-in support for context validation, transformation, and rollback mechanisms. These patterns ensure that as agents hand off tasks or collaborate on complex workflows, context flows predictably and errors don't cascade through the system. The result is multi-agent systems that can maintain coherent understanding across dozens of specialized agents, each contributing their expertise while preserving the overall task context.
Temporal Knowledge Graphs: Memory with a Time Dimension
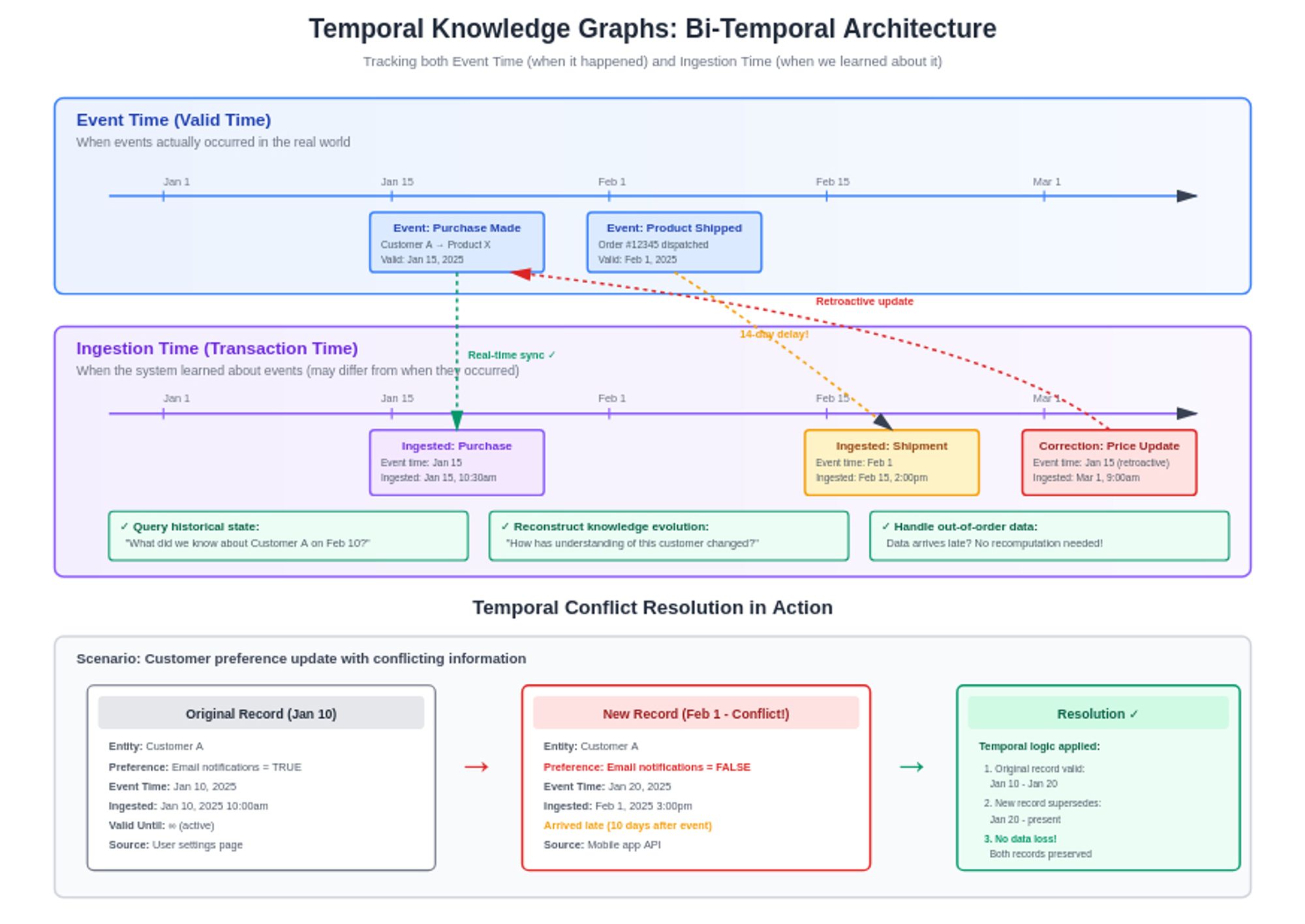
Temporal knowledge graphs represent a significant advancement in AI agent memory, with systems like Graphiti implementing bi-temporal models that track both when an event occurred and when it was ingested into the system. This dual timeline approach solves one of the most challenging problems in agent memory: handling information that arrives out of order or updates retroactively. Every relationship in these graphs includes explicit validity intervals, allowing agents to reason not just about what is true, but when it was true.
The power of temporal modeling becomes apparent when agents need to reconstruct historical understanding or track how information evolves. When conflicts arise between new and existing knowledge, Graphiti intelligently uses temporal metadata to update or invalidate outdated information without discarding it, preserving historical accuracy without requiring large-scale recomputation. An agent can answer questions like "What did we know about this customer's preferences last month?" or "How has our understanding of this market evolved over the past quarter?" This temporal awareness transforms agents from systems that merely remember to systems that understand the evolution of knowledge itself.
The implementation challenges are significant—as knowledge graphs grow, infrastructure becomes more complex, and teams may notice higher latency during deep traversals when the system has to look far to find the right information. Solutions are emerging that combine the best of both worlds: using vector search to quickly identify relevant subgraphs, then performing detailed graph traversals within those constrained regions. This hybrid approach maintains the rich relationship modeling of graphs while preserving the speed users expect from modern AI systems.
Agentic RAG and Self-Improving Memory Systems
The evolution from traditional RAG to Agentic RAG represents a fundamental shift in how AI systems interact with their own memory. Rather than simply retrieving and presenting information, modern systems implement self-editing capabilities that update facts, invalidate outdated information when needed, and continuously reorganize memory structures for optimal retrieval. These systems don't just accumulate information; they actively curate and refine their knowledge base.
Memory-enabled agents now implement sophisticated patterns like continuous evaluation suites with staged rollouts and automatic rollback, treating memory updates with the same rigor as code deployments. When an agent learns something new that contradicts existing knowledge, it doesn't simply overwrite the old information. Instead, it initiates a reconciliation process that might involve confidence scoring, source verification, or even reaching out to other agents for consensus. This approach prevents the gradual degradation of memory quality that plagued earlier systems.
The feedback loop between memory and performance has become increasingly sophisticated. Modern agents use reinforcement learning to optimize their memory strategies, learning which information to prioritize, when to summarize versus store verbatim, and how to organize knowledge for fastest retrieval. Some systems even implement meta-memory—memory about their own memory performance—allowing them to identify and correct systematic biases in what they remember or forget.
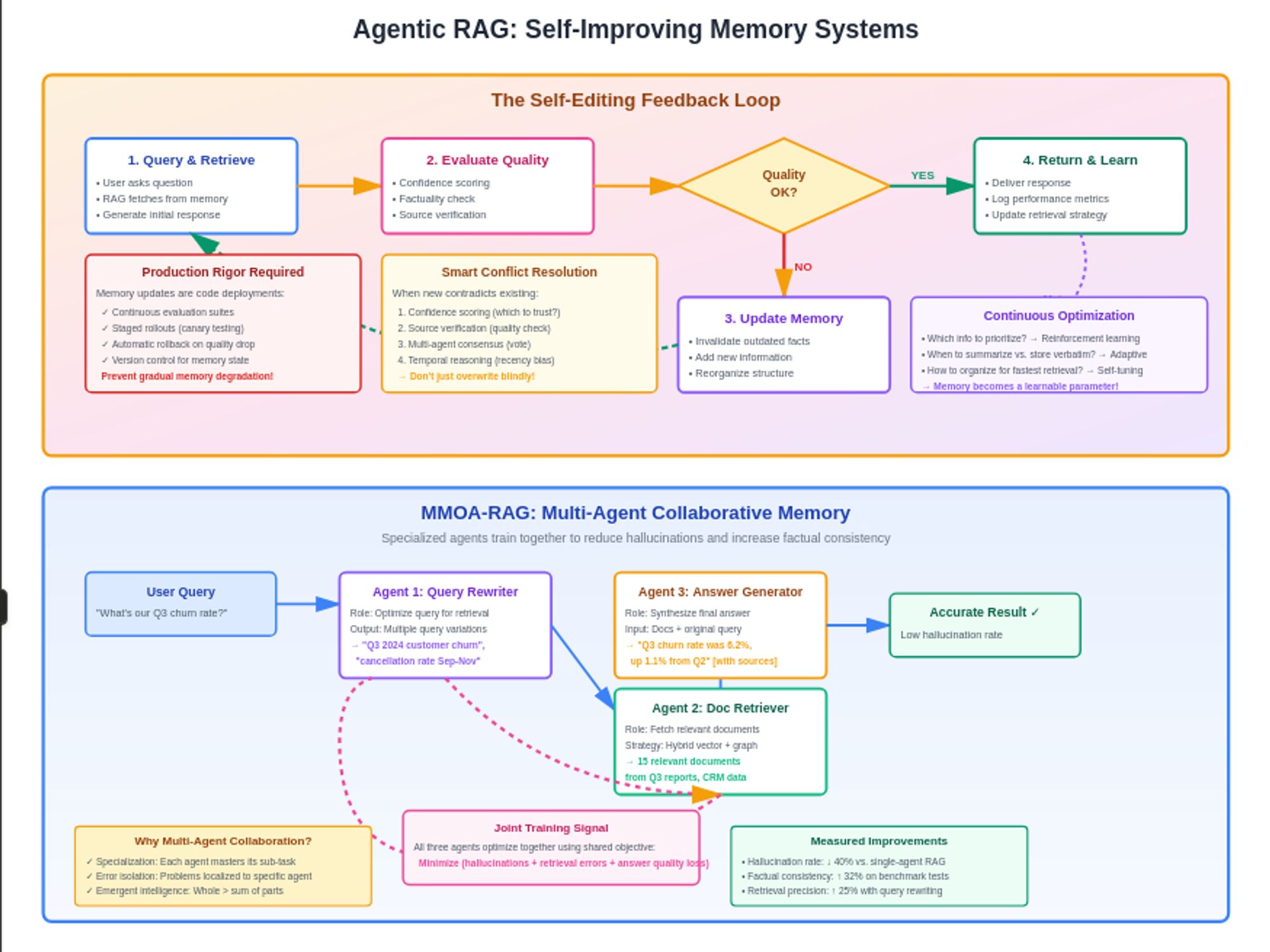
Multi-Agent Reinforcement Learning approaches like MMOA-RAG demonstrate how multiple specialized agents can collaborate to optimize memory systems, with agents responsible for query rewriting, document retrieval, and answer generation training together to reduce hallucinations and increase factual consistency. This collaborative approach to memory management suggests a future where memory isn't a static resource but a dynamic capability continuously optimized by the agent ecosystem itself.
Production Challenges and Solutions
Scaling Memory Systems: From Prototype to Production
The transition from demonstration to deployment reveals a harsh truth: memory systems that work beautifully in development often fall apart when real users start hitting them, struggling with load, cost overruns, and data leaks that can destroy user trust. The challenges multiply exponentially when scaling from single-user prototypes to systems serving millions of interactions daily. Memory bloat becomes a critical issue as agents accumulate vast amounts of potentially redundant or outdated information.
Organizations face several critical pain points in production: conversational agents tend to repeat themselves and demonstrate frustrating amnesia about previously established facts; systems repeatedly process identical contextual information, resulting in slower response times and substantially higher operational costs; and without persistent memory of user preferences, AI systems struggle to deliver truly personalized experiences that improve over time. These aren't just technical problems—they directly impact user experience and operational efficiency.
Solutions are emerging from both architectural innovations and operational best practices. Modern production systems implement sophisticated memory decay algorithms that automatically prune less frequently accessed memories, use tiered storage to move older memories to cheaper storage systems, and employ aggressive compression techniques that can reduce memory footprint by orders of magnitude without significant quality loss. Teams are learning to treat memory as a managed resource with explicit budgets, retention policies, and quality metrics.
Security and auditability have become paramount as agents gain autonomy, requiring multiple layers of protection including careful tool access control, execution validation before running agent-generated plans, sandboxed environments for untrusted code, granular permissions with API governance, and comprehensive logging through specialized platforms like LangSmith and AgentOps. These security measures must be built into the architecture from the beginning—retrofitting security into a production agent system is nearly impossible.
Looking Forward: The Future of Agent Memory
Convergent Evolution: Toward Cognitive Architectures
Neuro-symbolic AI is emerging as a particularly promising direction, merging deep learning with symbolic reasoning to address core limitations of pure neural networks while leveraging logic-based systems for transparency, knowledge integration, and error-checking. These hybrid systems can maintain both the intuitive, pattern-matching capabilities of neural networks and the precise, verifiable reasoning of symbolic systems. In memory terms, this means agents that can both "feel" their way to relevant memories through semantic similarity and logically traverse relationship chains to ensure consistency.
The development ecosystem itself is evolving to support this new paradigm, with tools and interfaces designed for a world where agents are both collaborators and consumers of software—where documentation is written as much for machines as for humans, and where Model Context Protocol (MCP) enables standardized memory sharing across agent boundaries. It seems we are moving toward an era where agent memory isn't isolated within individual systems but forms an interconnected web of knowledge that agents can traverse and contribute to collectively.
Despite speedy progress, fundamental challenges remain. Context switching and memory limitations mean most current agents struggle with maintaining context across long conversations or complex multi-day tasks, and while vector databases help with long-term memory, efficiently managing and retrieving relevant context at the right time remains an unsolved problem. This tension between memory completeness and computational efficiency forces constant trade-offs that limit agent capabilities.
At this inflection point, it seems clear that memory systems will be a step function towards the next generation of AI capabilities. The teams and organizations that solve the complexities of temporal knowledge graphs, context inheritance patterns, and distributed memory architectures will build the next generation of agents.